ALLPCB
ALLPCB



Rapid growth of large models
We are in the era of large models. In China alone, more than 200 large models have been officially released, and new models continue to appear. For example, China Agricultural University recently released the "Shennong" model, and NetEase released the "Ziyue" model version 2.0.
The level of intelligence emergence in a model is directly related to its parameter count, so increasing size remains the dominant approach for upgrading large models. For example, GPT-2 had 1.5 billion parameters, GPT-3 had 175 billion parameters (a 100x increase), and some reports place GPT-4 at about 1.8 trillion parameters (another roughly 10x increase).
As parameter count grows, the required training volume and compute increase accordingly. Any development or upgrade of a large model must account for compute constraints. Understanding the relationship between model scale and required compute is therefore essential for budgeting compute during model development.
Compute required grows roughly with the square of parameters
Transformer is the most widely used architecture for current models. Using Transformer-based large models as an example, model parameter count is mainly determined by the hidden dimension and the number of blocks. Let h denote the hidden dimension and i denote the number of blocks; the parameter count N scales with those quantities. Let b be the training batch size and s be the sequence length per input. The computation required for one training step scales with these factors; this relationship has been derived and validated in prior work.
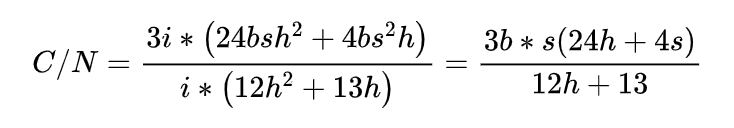
For models at the scale of tens to hundreds of billions of parameters, the hidden dimension h is much larger than the input sequence length s, so s can be neglected in the dominant terms. The expression above can be approximated to a form proportional to 6 b s, where b*s is the total token count per training batch. Denote this total token count as D.
We therefore obtain an estimate for the compute-equivalent required for training:
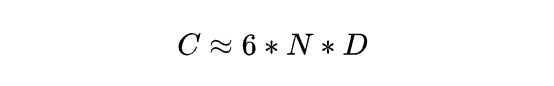
D and N are strongly correlated: larger models typically require more total training tokens. If we approximate the relationship as linear, N = k D where k is a constant, the formula becomes:
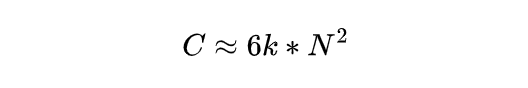
In other words, if model size doubles, required compute increases by a factor of four; if model size increases by 10x, required compute increases by 100x. Compute demand for large models grows faster than current compute technology improvements, making large-model development effectively a compute race. In practice, compute is already the main constraint on pushing model frontiers. From a cost perspective, training models at the scale of hundreds of billions or trillions of parameters exceeds what most organizations can afford; even well-funded organizations face extreme costs. For example, reported training runs for GPT-4 have been estimated to cost on the order of tens of millions of dollars per run.
How to allocate compute: size versus training tokens
There are two levers to improve model performance: increasing parameter count while reducing training tokens, or keeping parameter count fixed and increasing training tokens. Given limited compute, how should resources be allocated? Earlier work favored increasing model size. In 2020, OpenAI suggested that given a 10x compute budget, model size should increase by 5.5x while training token count should increase by 1.8x.
However, a 2023 study from DeepMind proposed a different approach: scale model size and training tokens proportionally. They argued that current large models are generally undertrained and that a thoroughly trained model requires about 20 tokens per parameter, while many large models have trained at levels closer to 10 tokens per parameter.
DeepMind trained the 70 billion-parameter Chinchilla model with about 1.4 trillion tokens; Chinchilla outperformed larger models such as Gopher (280 billion parameters), GPT-3 (175 billion parameters), and Megatron-Turing (530 billion parameters). Based on those results, the compute requirement for a properly trained model can be expressed quantitatively, showing that thorough training increases the effective compute proportional to the square of model size with a substantial constant factor. Put differently, achieving adequate training generally requires significantly more compute than earlier scaling rules implied.
After the DeepMind results, the rush to increase parameter counts slowed. Following the widespread arrival of hundred-billion-parameter models around 2022, most new models in 2023 (aside from GPT-4) did not push parameter counts to the trillion-parameter level; many new releases were in the tens to low hundreds of billions. Keeping model scale moderate while training more thoroughly can produce more desirable emergence of intelligence.
For example, Inspur's "Yuan" family shows this trend: version 1.0 had 245 billion parameters and performed well at zero-shot and few-shot tasks, while version 2.0 used a maximum of about 102.6 billion parameters but achieved stronger capabilities in logical reasoning, mathematics, and coding. The practical lesson is that investing additional compute to better train models in the hundreds of billions range can yield significant capability gains.
Smaller foundation models and skill-specific models derived from them impose lower hardware and energy demands during inference. If the parameter size of a foundation model is reduced by 1%, the inference compute for each derived skill model also decreases by about 1%, which has meaningful economic and societal implications.
Prioritizing compute development
AI is still at an early stage of development, and models are only beginning to enter the economy and everyday life. It is plausible that in the future each major scenario will have an associated large model, and individuals may use personalized large models as well. For a long period ahead, demand for model training compute will remain strong, and compute bottlenecks will be a long-term constraint on training and deployment.
Therefore, development of AI should prioritize expanding compute capacity. Both governments and companies should allocate more resources to the compute industry to support sustained progress in model training and deployment.