ALLPCB
ALLPCB


Overview
In deep learning object detection, especially face detection, small objects or small faces are challenging because of low resolution, blurring, limited information, and high noise. Over recent years, several practical methods have emerged to improve small object detection. This article analyzes and summarizes those approaches.
Traditional Image Pyramid and Multi-scale Sliding Window
Before deep learning became dominant, common practice for handling different object scales was to build an image pyramid of different resolutions and run a fixed-size classifier with a sliding window on each pyramid level to detect objects. The goal was to detect small objects at the bottom of the pyramid. Alternatively, one could run classifiers of different input resolutions on the original image so that smaller window classifiers could detect small objects.
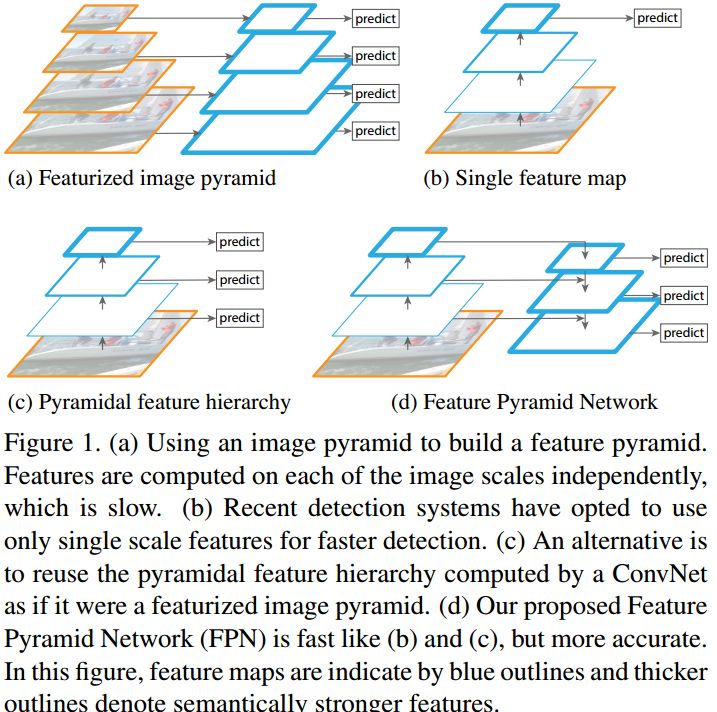
These methods are slow because they require multiple feature extraction passes, even though image pyramid construction can be accelerated by separable convolution or simple resizing. The feature pyramid network FPN borrowed this idea by fusing features from different layers so only one forward pass is needed and no image scaling is required. FPN has been widely applied for small object detection and is discussed further below.
Simple and Effective Data Augmentation
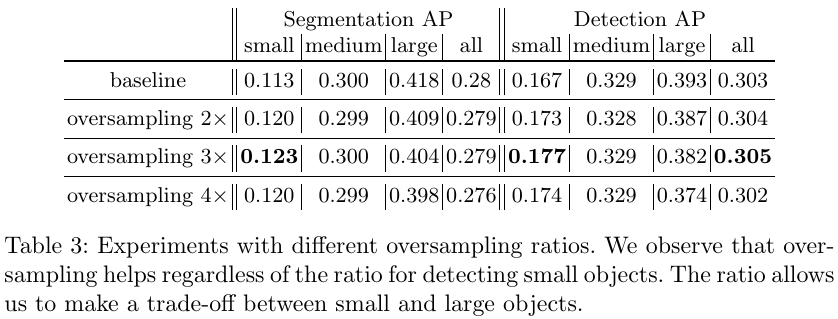
Deep learning performance depends heavily on training data volume. Small object detection can be improved by increasing the number and variety of small-object samples in the training set. Many augmentation techniques for class imbalance can also help when small-object instances are underrepresented. A 2019 paper, "Augmentation for Small Object Detection", proposed two straightforward methods:
Method 1
Use oversampling to increase the number of images that contain small objects in datasets such as COCO.
Method 2
Within an image that contains few small objects, extract small-object masks and paste the objects to new locations in the same image, optionally applying rotation and scaling. Care must be taken not to occlude other objects.
Feature Pyramid Networks (FPN)
Feature maps at different stages have different receptive fields and abstraction levels. Shallow feature maps have small receptive fields and are better suited for detecting small objects, since deep feature maps may see too much background noise for small objects. Conversely, deep feature maps have large receptive fields and are better for large objects. Fusing feature maps from multiple stages enhances detection across scales; this is the idea behind FPN.
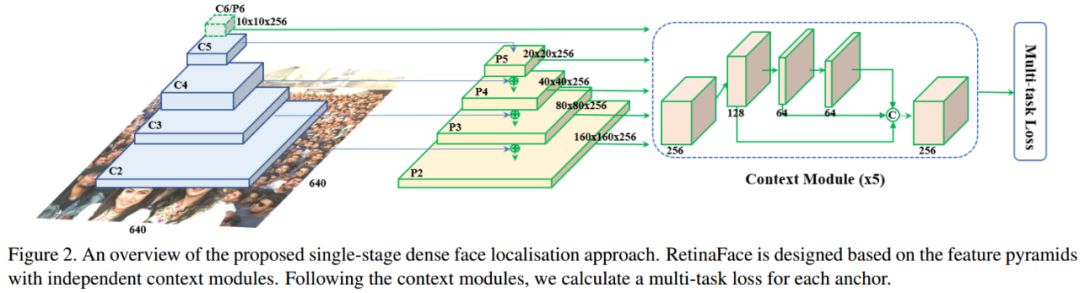
In face detection, many strong methods adopt the FPN idea. A representative example is RetinaFace: Single-stage Dense Face Localisation in the Wild.
Alternative: Use Different Feature Resolutions for Different Scales
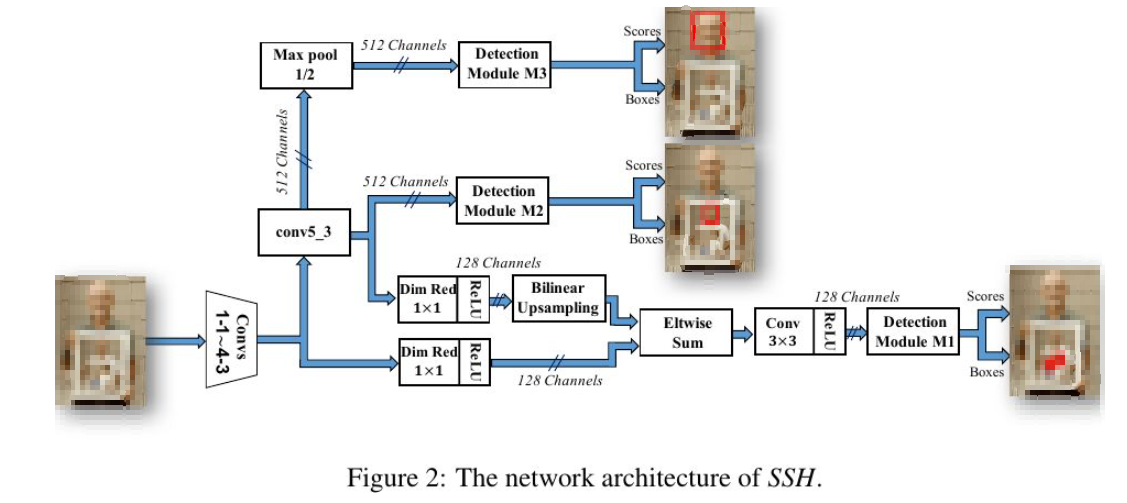
Since fusing different resolution feature maps improves richness and information content for multi-scale detection, another approach is to assign detection of different object sizes to different-resolution feature maps: use high-resolution shallow features for small faces, medium-resolution middle features for medium faces, and low-resolution deep features for large faces. This idea appears in methods such as SSH for face detection.
Appropriate Training Methods: SNIP, SNIPER, SAN
In machine learning, a key principle is that the pretraining distribution should match the test input distribution as closely as possible. A model trained on high-resolution inputs (for example 224 x 224) is not ideal for detecting images that are originally low-resolution and then upsampled. If the input images are low-resolution, training on low-resolution images is preferred. If that is not feasible, fine-tuning a high-resolution pretrained model on low-resolution images is the next best option. Directly using a model trained on high-resolution images to predict upsampled low-resolution images is the least desirable approach. In practice, enlarging input images, pretraining on high-resolution images, and then fine-tuning on small images often outperforms training a dedicated small-image classifier from scratch, given typical data availability.


The figure below illustrates the SNIP training method. During training, only object samples of appropriate scales are used. Ground-truth objects and anchors are considered valid for training only when their scales match; objects that are too small or too large are ignored. During inference, multi-scale input images ensure that at least one anchor size will be suitable for each object, and that scale is used for prediction. For R-FCN, the main improvements include multi-scale image input with validation of GT and anchors during RPN to produce more accurate proposals, and selecting proposals within a size range during the RCN stage before applying NMS to produce final results.
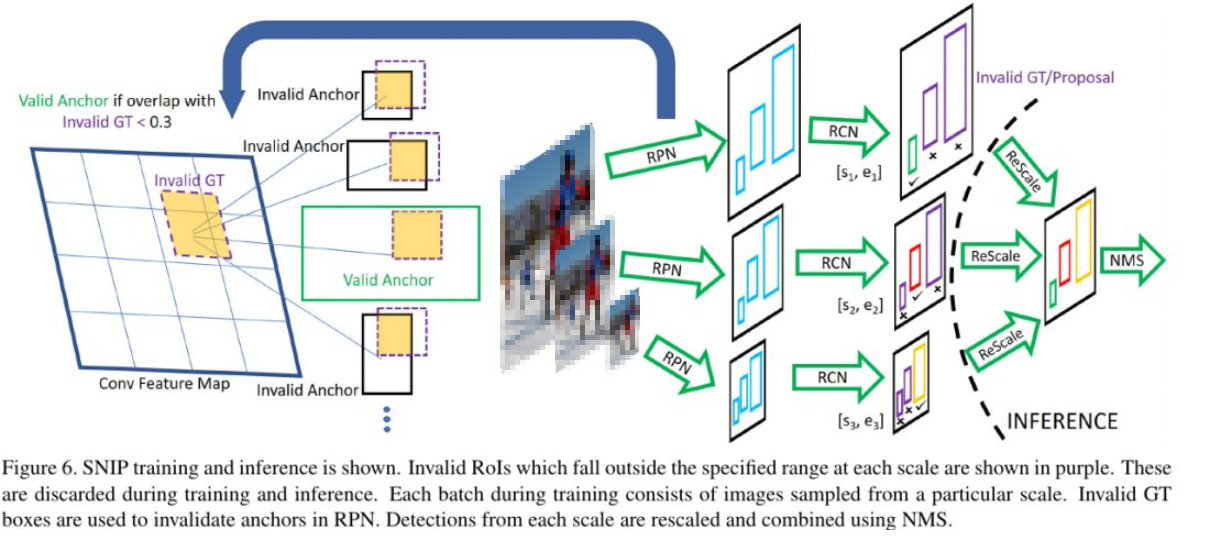
SNIPER is a practical extension of SNIP and is a more scalable implementation.
Dense Anchor Sampling and Matching Strategies: S3FD, FaceBoxes
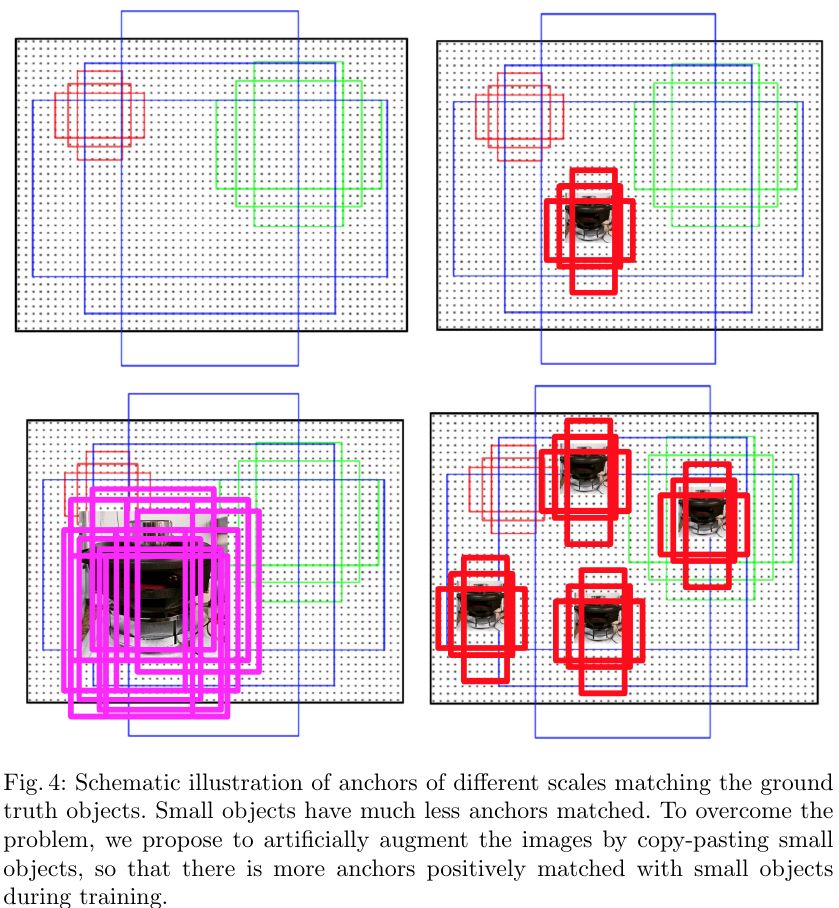
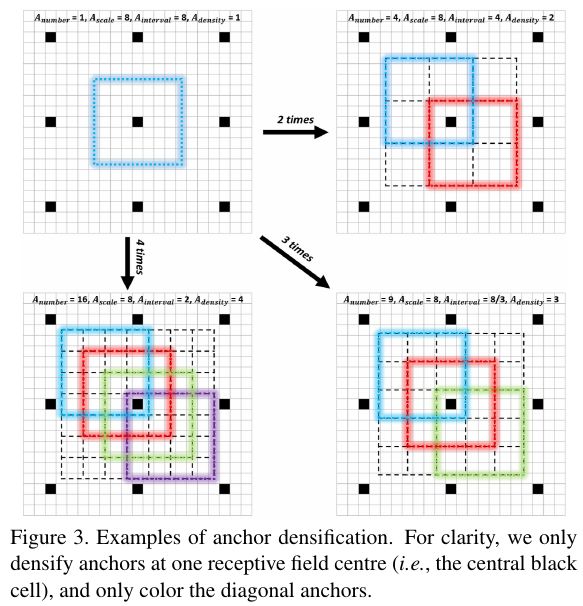
As mentioned in the data augmentation section, copying small objects to multiple locations within an image increases the number of positive anchors for small objects, boosting their training weight and reducing bias toward large objects. Alternatively, when the dataset is fixed, we can increase the density of anchors responsible for small objects to ensure more thorough training on small targets.
For example, FaceBoxes contributes an anchor densification strategy. Inception3 anchors have three scales (32, 64, 128), and the 32 scale is relatively sparse, so it is densified by 4x while the 64 scale is densified by 2x. S3FD uses the equal-proportion interval principle to ensure that anchors for different sizes have roughly equal density in the image, so large and small faces match a similar number of anchors.
Using a looser matching threshold for small-object anchors, such as IoU > 0.4, is also a common practice.
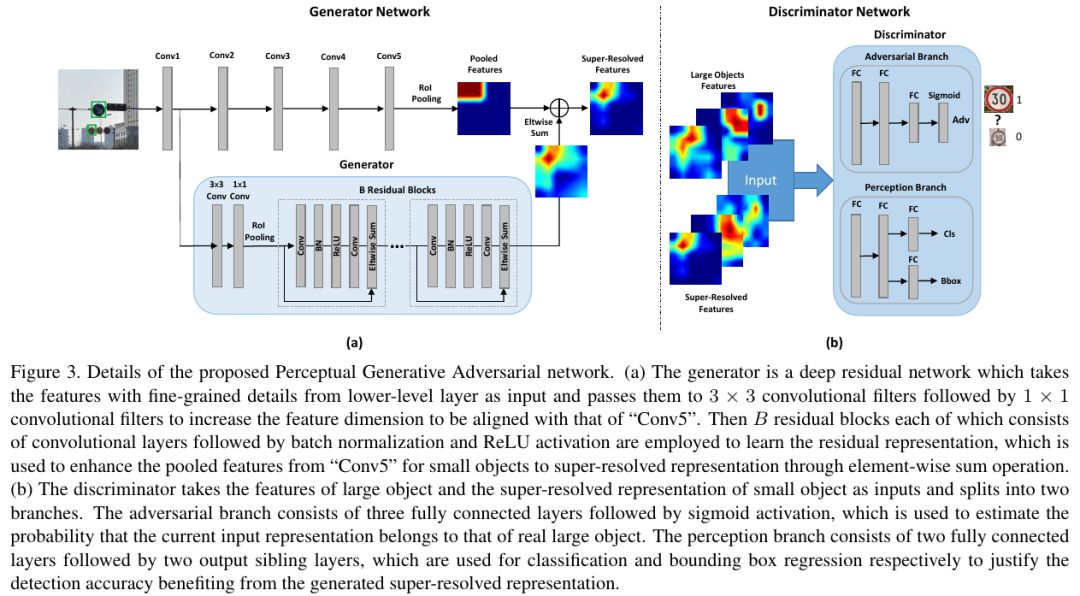
Generate Enlarged Features First via GAN
Perceptual GAN uses a generative adversarial network to produce a super-resolved feature representation for small objects that resembles the features of large objects. The super-resolved feature is then added to the original small-object feature map to enhance the feature representation and improve detection performance, demonstrated for traffic light detection in the paper.

Using Context: Relation Network and PyramidBox
Small objects, especially faces, rarely appear in isolation. For example, a face without head, shoulders, or a body is unlikely. Methods like PyramidBox add contextual cues such as head and shoulder regions so that the effective object becomes larger and easier to detect. This context augmentation clarifies ambiguous small-object features.

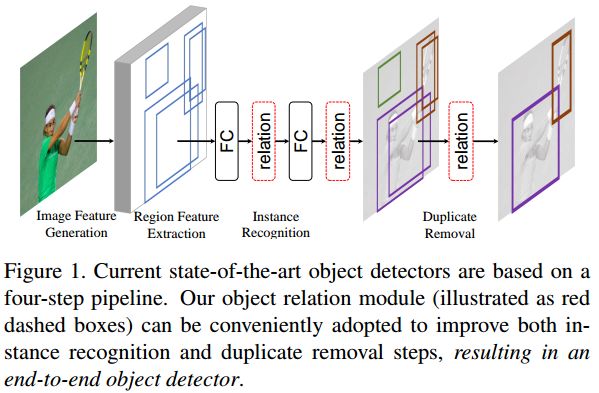
Another context-based idea in general object detection is Relation Networks, which focus on improving recognition and suppressing duplicate detections by modeling relationships among objects. Though not specifically designed for small-object detection, Relation Networks share the PyramidBox idea of leveraging context to improve detection.
Summary
This article summarizes common solutions for small-object detection in general object detection and face detection. Future notes may cover specific face detection challenges, such as extreme pose variations, and current academic solutions.